Logistic回归实际上是一种分类模型. 在线性回归中, 我们构建了一个超平面使得这个平面尽可能地经过所有的点. 而逻辑回归则恰恰相反, 需要将样本尽可能地分成两堆, 使得每一个样本属于其划分的可能性最高. 当然, 这个划分是先验信息, 所以逻辑回归属于有监督学习的一种. 本文分别用梯度下降法和牛顿迭代法实现二类的logistic回归.
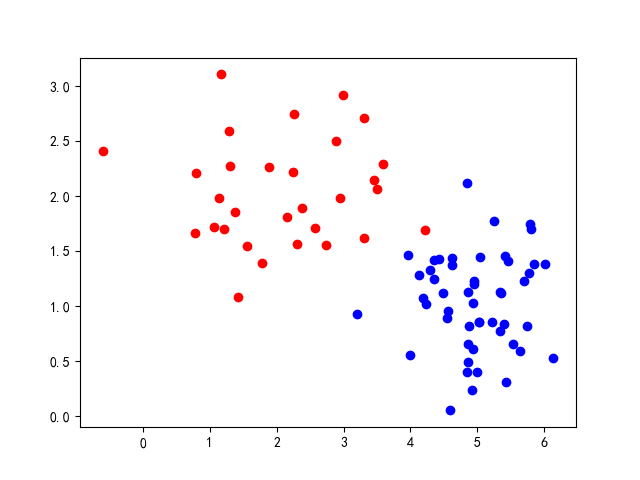
简单的二分类模型
考虑最理想的情况, 如果能找到这样一种函数, 输入样本, 如果输出为1, 那么样本就在分类1中, 如果输出0, 那么样本就在分类2中. 而符号函数就符合我们的需要, 对于任意的, 它的取值不是0,就是1.
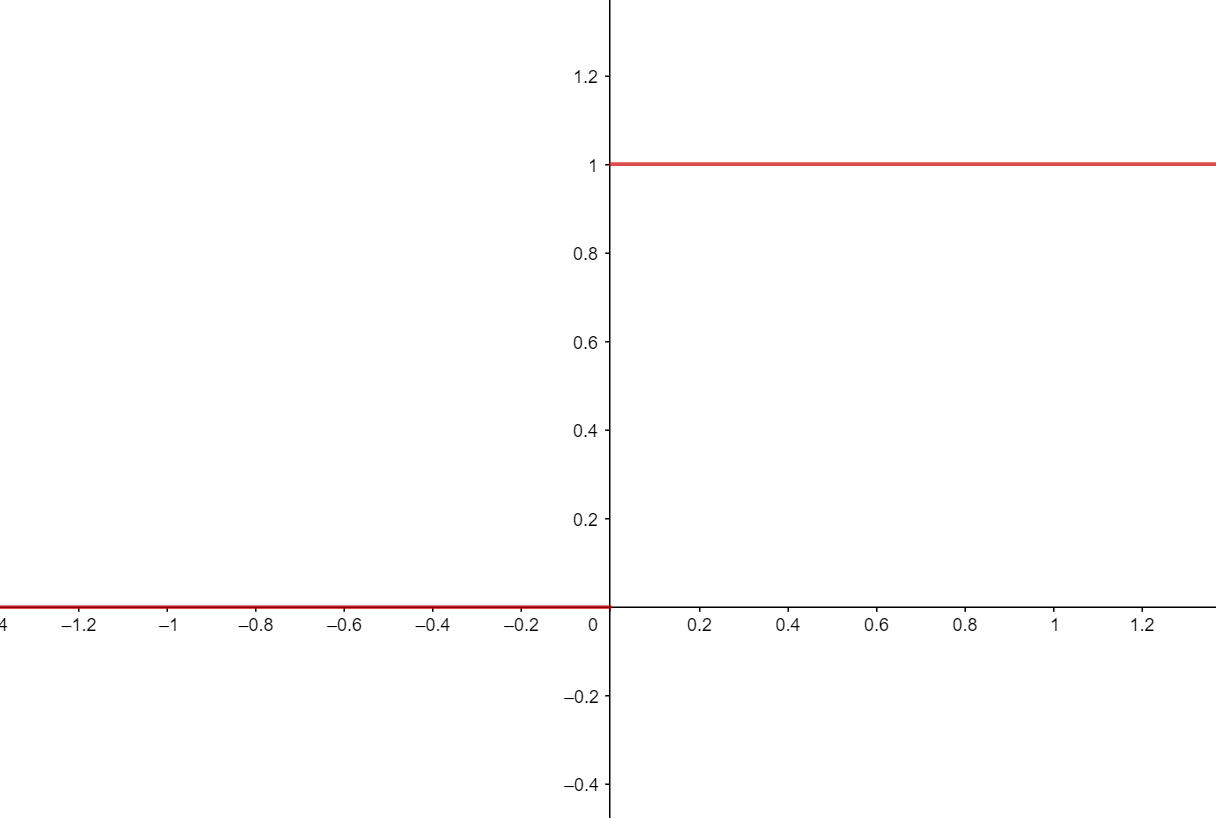
理想很美好, 但是符号函数并不好用. 原因之一就是它在定义域上不连续. 如果我们想对它进行求导或者其他什么运算, 将变的困难重重. 因此,如果能有一种函数, 它既类似于符号函数, 在定义域上又连续, 还高阶可导那就好了. 幸运的是,我们找到了逻辑函数, 即图中的紫色曲线.
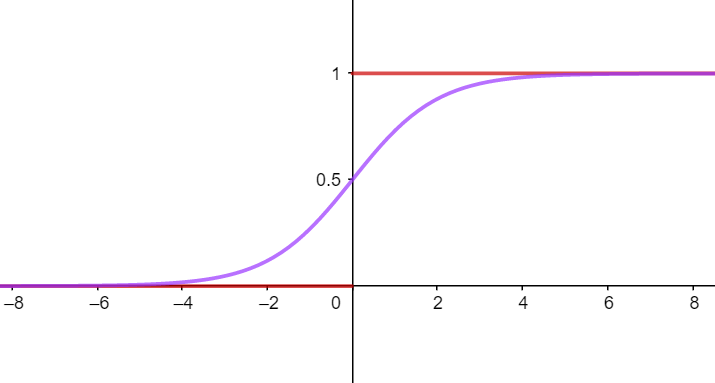
逻辑函数将样本映射到值域之间, 并且它单调可微, 有着十分良好的数学性质. 其数学形式如下:
接下来就很简单了, 对于样本中给的不同特征, 希望找到合适的与其相乘, 最后将结果求和, 代入到函数中, 并且按照如下公式分类:
这样, 问题就转变为如何找到这样一组合适的, 使得所有样本尽可能地划分为它应该属于的分类里去. 考虑最大似然函数:
其中分别为:
为了每一个样本都尽可能的划分到正确分类, 就要使得似然函数取到最大值.
连乘计算较为困难, 一般使用对数最大似然估计, 它们在求解最大值上几乎是等价的. 同时处于习惯, 为其添加负号, 这样就变成了求解负对数似然函数的最小值. 事实上, 负对数似然函数也是凸函数, 我们依然可以使用线性回归中学到的梯度下降法求解.
其中为学习率, 为负对数似然函数的梯度.
除此之外, 还值得学习另外一种方法: 牛顿迭代法.
在这里简要地说明一下原理.
考虑连续高阶可导函数在某邻域处的泰勒展开, 并取其前2项:
令, 得到:
所以, 如果有解, 我们总是能通过迭代的方式得到该解.
并且我们知道是凸的, 最小值点就位于导数为零的点. 我们可以对函数的导数迭代, 其结果和原函数一样的.
梯度下降法
公式准备
为了方便起见, 我们先求一下函数的导数
而成本函数
对成本函数求导得到:
并且进行向量化, 方便计算:
综上, 得到了一个迭代公式:
只要我们将上述过程编程代码, 就很容易得到想要的程序了.
python实现
引用库:
import numpy as np
import pandas as pd
import time
import data_in # 导入数据
import matplotlib.pyplot as plt导入数据以及处理:
def data_np_lr(): # 数据导入
return np.array(pd.read_table('./data/LR_data.txt'))
def normalization(data): # 归一化, 并对X添加一列常数项
ones = np.ones((data.shape[0], 1))
data = (data - np.min(data, axis=0)) / (np.max(data, axis=0) - np.min(data, axis=0))
return np.append(ones, data, axis=1)梯度下降法实现:
# 定义Sigmoid函数
def sigmoid(z):
return 1.0 / (1.0 + np.exp(-z))
# 定义成本函数
def cost(X, theta, y):
m, n = X.shape
h = sigmoid((np.dot(X,theta)))
cost = (-1.0/m) * np.sum(y.T * np.log(h)
+ (1- y).T * np.log( 1 - h))
return cost
# 梯度迭代下降
def LR_gradient(X, y, alpha=0.01, tol=1e-4, max_iter=100000):
process = max_iter / 100 # 显示进度
# matrix 更为方便
X = np.mat(X)
y = np.mat(y)
m, n = X.shape
theta = np.ones((n, 1))
loss = 1
iter = 0
while (iter < max_iter):
loss = cost(X, theta, y)
# 梯度的下降法
h = sigmoid(np.dot(X, theta)) # 预测值
error = h - y # 误差项
grad = (1.0 / m) * np.dot(X.T, error) # 梯度
theta = theta - alpha * grad
if (iter % process == 0):
print("|", end="")
if np.all(np.absolute(grad) <= tol):
break
iter += 1
print("\n迭代:", iter, "次", " 最大迭代次数: ", max_iter, "损失: ", loss)
return theta预测结果
def predict(X, theta, y):
m, n = X.shape
pre = np.zeros((m,1))
for i in range(m):
map = sigmoid(np.dot(X[i,:],theta))
if map > 0.5:
pre[i] = 1
count = 0
for i in range(m):
if (pre[i] == y[i]):
count +=1
return count / m结果可视化:
def paint_result(X, y, w):
fig = plt.figure()
ax = fig.add_subplot(111)
for i in range(X.shape[0]):
if y[i] == 1:
ax.scatter(X[i][1], X[i][2],color="red")
else :
ax.scatter(X[i][1], X[i][2], color="green")
x = np.arange(min(X[:,1]),max(X[:,1]),0.001)
y = (-w[0] - w[1] * x.T)/w[2]
ax.plot(x, y.getA1())
plt.show()主函数:
if __name__ == '__min__':
file_read = data_in.data_np_lr() # 小规模训练集
rows, columns = file_read.shape
beta = 0.8 # 训练集占比
# 训练集
X_tr = normalization(file_read[:int(rows*beta), :columns - 1])
y_tr = file_read[:int(rows*beta), -1:]
# 测试集
X_test = normalization(file_read[int(rows*beta):, :columns - 1])
y_test = file_read[int(rows*beta):,-1:]
print("Logistic Regression 梯度下降算法")
time_start = time.time()
theta_1 = LR_gradient(X_tr, y_tr,alpha=0.05, tol=1e-4,max_iter=1e6)
time_end = time.time()
print("测试集预测准确率: ",predict(X_test,theta_1,y_test),end="//")
print('time cost', time_end - time_start, 's')
# 绘制结果
paint_result(X_tr, y_tr, theta_1)
paint_result(X_test, y_test, theta_1)查看效果
先得到函数输出:
Logistic Regression 梯度下降算法
迭代: 594006 次 最大迭代次数: 1000000.0 损失: 0.09410151721717233
测试集预测准确率: 0.95//time cost 53.365071296691895 s将数据可视化,来看一下训练集迭代结果:
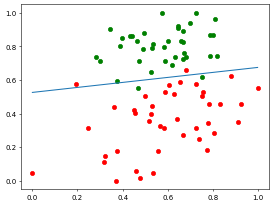
用测试集来评价训练集训练的效果:
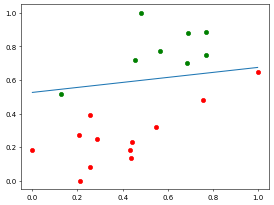 效果喜人!
效果喜人!
牛顿迭代法
牛顿迭代法和梯度下降法大同小异, 只是迭代过程多了一个步骤, 需要求解二阶导而已.
代码实现:
类似于上述代码, 只需添加:
def newtons_method_gradient(X, theta ,y): # 求解一阶偏导
m, n= X.shape
return (1.0/m) * np.dot(X.T, sigmoid( np.dot(X, theta)) - y)
def newtons_method_hessian(X, theta ,y): # 负最大对数似然函数的二阶Hessian矩阵
p = sigmoid( np.dot(X, theta))
q = p.getA1()
'''
p 必须使用getA1()方法转化为一维的数组.
在numpy中, array([12, 23, 34]) 和 array([[12, 23, 34]])并不完全相同
而在此处, 可能由于版本原因, 很多网上很多教程使用np.diag(array([[]]))是
可以得到正常的对角矩阵的, 而我的环境已经不支持这样做了, 只会一维矩阵的形式返回
结果
所以, 必须使用getA1()方法, 将p强制转换为数组, 这样np.diag()方法才能将数组正常
地转化为对角矩阵, 而不是以一维数组的方式返回
'''
return (1.0/m)*X.T.dot(np.diag(q * (1-q)).dot(X))
def LR_newton(X, y, tol = 1e-6, max_iter = 10000):
process= max_iter / 100
X = np.mat(X)
y = np.mat(y)
m, n = X.shape
theta = np.zeros((n,1))
loss = 1
iter = 0
while( iter < max_iter):
loss = cost(X,theta, y)
# 牛顿迭代法
grad = newtons_method_gradient(X, theta, y)
hessian = newtons_method_hessian(X, theta, y)
theta = theta - np.linalg.inv(hessian) * grad
if iter % process == 0:
print("|",end="")
if np.all(np.absolute(grad) <= tol):
break
iter += 1
print("\n迭代:",iter,"次",",最大迭代次数: ", max_iter, "损失: ",loss)
return theta只需调用函数即可:
theta_1 = LR_newton(X_tr, y_tr, tol=1e-5,max_iter=1e5)输出结果:
Logistic Regression 牛顿迭代法
迭代: 7 次 ,最大迭代次数: 10000.0 损失: 0.09400816347426497
测试集预测准确率: 0.95//time cost 0.001995563507080078 s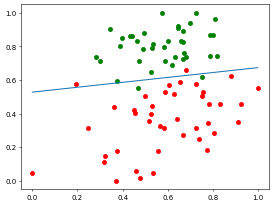
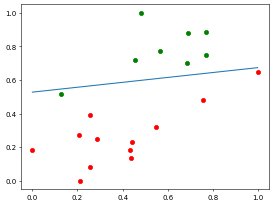
可以看到, 牛顿迭代法得到的损失函数很小, 并且迭代次数少, 在合适的条件下甚至能得到比梯度下降更快的结果.
而且牛顿迭代法并不需要手动设置步长, 减少了超参调整这一环节的很多麻烦细节.
小技巧: 如何构建自己想要的样本
如果我们在做作业的时候, 发现课程给的数据集很大, 并且训练效果不是很好, 在初步入门的时候会产生很多困扰. 怀疑自己是不是写错了, 或者有时候想验证自己的方法正确与否, 可是训练一次又要花费大半天的时间. 于是我们可以构建一个较小而且可控的数据样本作为自己的训练集
# 生成80个数据
for i in range(50):
# 归于蓝方
one = random.gauss(5, 0.5) # 均值, 标准差
two = random.gauss(1,0.5)
x_1.append(one)
x_2.append(two)
for i in range(30):
# 归于红方
one = random.gauss(2,1)
two = random.gauss(2,0.5)
y_1.append(one)
y_2.append(two)
plt.scatter(x_1, x_2, color="blue")
plt.scatter(y_1, y_2,color="red")
plt.show()这里代码的写法只是为了作图方便, 实际上大可以直接生成一个numpy矩阵, 这样, 只要我们给定一些分布的参数, 就足以能够创造一个精巧的数据集了. 事实上, 封面的数据集合就是这段代码做出的!
登录后评论
评论需要先登录。
登录